强化学习基础篇 OpenAI Gym 环境搭建demo
淘宝搜:【天降红包222】领超级红包,京东搜:【天降红包222】
淘宝互助,淘宝双11微信互助群关注公众号 【淘姐妹】
Gym是一个研究和开发强化学习相关算法的仿真平台,无需智能体先验知识,由以下两部分组成
- Gym开源库:测试问题的集合。当你测试强化学习的时候,测试问题就是环境,比如机器人玩游戏,环境的集合就是游戏的画面。这些环境有一个公共的接口,允许用户设计通用的算法。
- OpenAI Gym服务:提供一个站点和API(比如经典控制问题:CartPole-v0),允许用户对他们的测试结果进行比较。
我们需要在Python 3.5+的环境中简单得使用pip安装gym
如果需要从源码安装gym,那么可以:
可以运行pip install -e .[all]执行包含所有环境的完整安装。 这需要安装一些依赖包,包括cmake和最新的pip版本。
简单来说OpenAI Gym提供了许多问题和环境(或游戏)的接口,而用户无需过多了解游戏的内部实现,通过简单地调用就可以用来测试和仿真。接下来以经典控制问题CartPole-v0为例,简单了解一下Gym的特点
运行效果如下
?
以上代码中可以看出,gym的核心接口是Env。作为统一的环境接口,Env包含下面几个核心方法:
- reset(self):重置环境的状态,返回观察。
- step(self, action):推进一个时间步长,返回observation, reward, done, info。
- render(self, mode=‘human’, close=False):重绘环境的一帧。默认模式一般比较友好,如弹出一个窗口。
- close(self):关闭环境,并清除内存
以上代码首先导入gym库,然后创建CartPole-v0环境,并重置环境状态。在for循环中进行1000个时间步长控制,env.render()刷新每个时间步长环境画面,对当前环境状态采取一个随机动作(0或1),在环境返回done为True时,重置环境,最后循环结束后关闭仿真环境。
在上面代码中使用了env.step()函数来对每一步进行仿真,在Gym中,env.step()会返回 4 个参数:
- 观测 Observation (Object):当前step执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
- 奖励 Reward (Float): 执行上一步动作(action)后,智能体( agent)获得的奖励(浮点类型),不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
- 完成 Done (Boolen): 表示是否需要将环境重置 env.reset。大多数情况下,当 Done 为True 时,就表明当前回合(episode)或者试验(tial)结束。例如当机器人摔倒或者掉出台面,就应当终止当前回合进行重置(reset);
- 信息 Info (Dict): 针对调试过程的诊断信息。在标准的智体仿真评估当中不会使用到这个info,具体用到的时候再说。
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。所以更恰当的方法是遵守done的标志。
代码运行结果的片段如下所示:
上面的结果可以看到这个迭代中,输出的观测为一个列表。这是CartPole环境特有的状态,其规则是。
其中:
- 表示小车在轨道上的位置(position of the cart on the track)
- 表示杆子与竖直方向的夹角(angle of the pole with the vertical)
- 表示小车速度(cart velocity)
- 表示角度变化率(rate of change of the angle)
每次执行的动作(action)都是从环境动作空间中随机进行选取的,但是这些动作 (action) 是什么?在 Gym 的仿真环境中,有运动空间 action_space 和观测空间observation_space 两个指标,程序中被定义为 Space类型,用于描述有效的运动和观测的格式和范围。下面是一个代码示例:
从程序运行结果可以看出:
- action_space 是一个离散Discrete类型,从discrete.py源码可知,范围是一个{0,1,…,n-1} 长度为 n 的非负整数集合,在CartPole-v0例子中,动作空间表示为{0,1}。
- observation_space 是一个Box类型,从box.py源码可知,表示一个 n 维的盒子,所以在上一节打印出来的observation是一个长度为 4 的数组。数组中的每个元素都具有上下界。
在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env会返回一个+1的reward。其中CartPole-v0中到达200个reward之后,游戏也会结束,而CartPole-v1中则为500。最大奖励(reward)阈值可通过前面介绍的注册表进行修改。
Gym是一个包含各种各样强化学习仿真环境的大集合,并且封装成通用的接口暴露给用户,查看所有环境的代码如下
Gym支持将用户制作的环境写入到注册表中,需要执行 gym.make()和在启动时注册register。如果要注册自己的环境,那么假设你在以下结构中定义了自己的环境:
i. myenv.pyinit.py中,输入以下代码:
ii. 要使用我们自己的环境:
iii. 在PYTHONPATH中安装目录或从父目录启动python。
用户可以记录和上传算法在环境中的表现或者上传自己模型的Gist,生成评估报告,还能录制模型玩游戏的小视频。在每个环境下都有一个排行榜,用来比较大家的模型表现。
上传于录制方法如下所示
使用Monitor Wrapper包装自己的环境,在自己定义的路径下将记录自己模型的性能。支持将一个环境下的不同模型性能写在同一个路径下。
在官网注册账号后,可以在个人页面上看到自己的API_Key,接下来可以将结果上传至OpenAI Gym:
然后得到如下结果:
打开链接会有当前模型在环境下的评估报告,并且还录制了小视频:
每次上传结果,OpenAI Gym都会对其进行评估。
创建一个Github Gist将结果上传,或者直接在upload时传入参数:
评估将自动计算得分,并生成一个漂亮的页面。
在大多数环境中,我们的目标是尽量减少达到阈值级别的性能所需的步骤数。不同的环境都有不同的阈值,在某些环境下,尚不清楚该阈值是什么,此时目标是使最终的表现最大化。在cartpole这个环境中,阈值就是立杆能够直立的帧数。
任何程序错误,以及技术疑问或需要解答的,请添加
强化学习基础篇(十)OpenAI Gym环境汇总
Gym中从简单到复杂,包含了许多经典的仿真环境,主要包含了经典控制、算法、2D机器人,3D机器人,文字游戏,Atari视频游戏等等。接下来我们会简单看看主要的常用的环境。在Gym注册表中有着大量的其他环境,就没办法介绍了。
经典的强化学习示例,方便入门,包括了:
-
Acrobot-v1
Acrobot机器人系统包括两个关节和两个连杆,其中两个连杆之间的关节可以被致动。 最初,连杆是向下悬挂的,目标是将下部连杆的末端摆动到给定的高度。
Acrobot-v1.gif -
CartPole-v1
CartPole-v1环境中,手推车上面有一个杆,手推车沿着无摩擦的轨道移动。 通过对推车施加+1或-1的力来控制系统。 钟摆最开始为直立状态,训练的目的是防止其跌落。 杆保持直立的每个时间步长都提供+1的奖励。 当杆与垂直线的夹角超过15度时,或者推车从中心移出2.4个单位以上时,训练结束。
cartpole.gif -
MountaiCar-v0
MountaiCar-v0环境中汽车位于一维轨道上,轨道位于两个“山”之间。 目标是让汽车驶向右侧的山峰; 由于汽车的引擎强度不足以直接到达右侧山峰,所以,成功的唯一方法是来回驱动以产生动力。
MountainCar-v0.gif -
MountainCarContinuous-v0
MountainCarContinuous-v0环境与MountaiCar-v0环类似,动力不足的汽车必须爬上一维小山才能到达目标。 与MountainCar-v0不同,动作(应用的引擎力)允许是连续值。目标位于汽车右侧的山顶上。 如果汽车到达或超出,则剧集终止。
MountainCarContinuous-v0.gif -
Pendulum-v0
倒立摆摆动问题是控制文献中的经典问题。 在此问题的版本中,摆锤开始于随机位置,目标是将其摆动以使其保持直立。
Pendulum-v0.gif
从例子中学习强化学习的相关算法,在Gym的仿真算法中,由易到难方便新手入坑,包括了:
-
Copy-v0
此任务就是让智能体学习对序列的拷贝操作。
Copy-v0.gif -
DuplicatedInput-v0
此任务让智能体学习从输入序列,输出对每个元素的三次复制
DuplicatedInput-v0.gif -
RepeatCopy-v0
此任务让智能体学习对输入序列,输出对序列的m次复制。
RepeatCopy-v0.gif -
Reverse-v0
目的是反转输入序列
Reverse-v0.gif -
ReversedAddition-v0
此任务让智能体学习在提供的网格数字序列之上增加数字序列。在这个任务中需要智能体学会(i)记住加法表; (ii)学习如何在输入网格上移动,以及(iii)发现进位的概念。
ReversedAddition-v0.gif -
ReversedAddition3-v0
ReversedAddition3-v0与ReversedAddition-v0基本任务相同,但是现在要添加三个数字。 由于奖励信号的更具有稀疏性,因此难度加大(因为必须先完成更多正确的操作,然后才能产生正确的输出结果)。
ReversedAddition3-v0.gif
-
BipedalWalker-v2
这个环境要训练机器人向前移动,走到最远的位置一共有奖励300+,如果摔倒奖励-100。
环境的状态包括了船体角速度,角速度,水平速度,垂直速度,关节位置和关节角速度,腿是否与地面的接触以及10个激光雷达测距仪的测量值。( hull angle speed, angular velocity, horizontal speed, vertical speed, position of joints and joints angular speed, legs contact with ground, and 10 lidar rangefinder measurements.)状态向量中没有坐标。
BipedalWalker-v2.gif -
BipedalWalkerHardcore-v2
与BipedalWalker-v2相比,增加了一些障碍物。
BipedalWalkerHardcore-v2.gif -
CarRacing-v0
CarRacing-v0是一个最简单的连续控制任务。智能体从环境的图片像素中学习。这个环境也可以进行离散动作控制,环境带有离散化的开关控制是否进行离散化的动作控制。状态是由96x96的像素组成。 奖励是每帧-0.1。到达每个预定义位置会有+1000/N的奖励,所以环境里面有N个小目标。
例如,智能体在732帧完成目标,则奖励为1000-0.1 * 732=926.8。 赛车碰到边界就结束。窗口底部会显示一些指标。 从左到右为:真实速度,四个ABS传感器,方向盘位置,陀螺仪。
CarRacing-v0.gif -
LunarLander-v2
这是一个控制智能体着陆到指定目标的任务。
Landing pad is always at coordinates (0,0). Coordinates are the first two numbers in state vector. Reward for moving from the top of the screen to landing pad and zero speed is about 100..140 points. If lander moves away from landing pad it loses reward back. Episode finishes if the lander crashes or comes to rest, receiving additional -100 or +100 points. Each leg ground contact is +10. Firing main engine is -0.3 points each frame. Solved is 200 points. Landing outside landing pad is possible. Fuel is infinite, so an agent can learn to fly and then land on its first attempt. Four discrete actions available: do nothing, fire left orientation engine, fire main engine, fire right orientation engine.
LunarLander-v2.gif -
LunarLanderContinuous-v2
LunarLander-v2的连续控制版本
Landing pad is always at coordinates (0,0). Coordinates are the first two numbers in state vector. Reward for moving from the top of the screen to landing pad and zero speed is about 100..140 points. If lander moves away from landing pad it loses reward back. Episode finishes if the lander crashes or comes to rest, receiving additional -100 or +100 points. Each leg ground contact is +10. Firing main engine is -0.3 points each frame. Solved is 200 points. Landing outside landing pad is possible. Fuel is infinite, so an agent can learn to fly and then land on its first attempt. Action is two real values vector from -1 to +1. First controls main engine, -1..0 off, 0..+1 throttle from 50% to 100% power. Engine can't work with less than 50% power. Second value -1.0..-0.5 fire left engine, +0.5..+1.0 fire right engine, -0.5..0.5 off.
LunarLanderContinuous-v2.gif
MuJoCo(Multi-Joint dynamics with Contact)是一个物理模拟器,可以用于机器人控制优化等研究。
-
Ant-v2
需要训练一个四足的智能体学会行走。
Ant-v2.gif -
HalfCheetah-v2
需要训练一个两足的智能体学会行走。
HalfCheetah-v2.gif -
Hopper-v2
需要训练一个单腿的智能体向前跳跃
Hopper-v2.gif -
Humanoid-v2
需要训练三维双足智能体尽可能快地向前走,并且不会摔倒。
Humanoid-v2.gif -
HumanoidStandup-v2
需要训练尽可能快地让使三维双足智能体学会站立。
HumanoidStandup-v2.gif -
InvertedDoublePendulum-v2
需要智能体学会保持连杆不要掉下来
InvertedDoublePendulum-v2.gif InvertedPendulum-v2
-
Reacher-v2
训练智能体不断去接近一个目标。
Reacher-v2.gif -
Swimmer-v2
此任务涉及在粘性流体中的三连杆游泳智能体,其目的是通过控制两个关节,使其尽可能快地向前游泳。
Swimmer-v2.gif -
Walker2d-v2
需要训练使二维双足智能体尽可能快地向前走。
Walker2d-v2.gif
利用强化学习来玩雅达利的游戏。Gym中集成了对强化学习有着重要影响的Arcade Learning Environment,并且方便用户安装;
游戏的目标都是为了在游戏中最大化游戏分数。但是他们的状态分为两类,一类是直接观测屏幕的像素输出,另一类是观测到RAM中的数据。所有的环境名称列在下表中:
| 游戏名称 | 环境名称(屏幕输出) | 环境名称(RAM) |
|---|---|---|
| AirRaid | AirRaid-v0 | AirRaid-ram-v0 |
| Alien | Alien-v0 | Alien-ram-v0 |
| Amidar | Amidar-v0 | Amidar-ram-v0 |
| Assault | Assault-v0 | Assault-ram-v0 |
| Asterix | Asterix-v0 | Asterix-ram-v0 |
| Asteroids | Asteroids-v0 | Asteroids-ram-v0 |
| Atlantis | Atlantis-v0 | Atlantis-ram-v0 |
| BankHeist | BankHeist-v0 | BankHeist-ram-v0 |
| BattleZone | BattleZone-v0 | BattleZone-ram-v0 |
| BeamRider | BeamRider-v0 | BeamRider-ram-v0 |
| Berzerk | Berzerk-v0 | Berzerk-ram-v0 |
| Bowling | Bowling-v0 | Bowling-ram-v0 |
| Boxing | Boxing-v0 | Boxing-ram-v0 |
| Breakout | Breakout-v0 | Breakout-ram-v0 |
| Carnival | Carnival-v0 | Carnival-ram-v0 |
| Centipede | Centipede-v0 | Centipede-ram-v0 |
| ChopperCommand | ChopperCommand-v0 | ChopperCommand-ram-v0 |
| CrazyClimber | CrazyClimber-v0 | CrazyClimber-ram-v0 |
| DemonAttack | DemonAttack-v0 | DemonAttack-ra中国版chatgpt即将面世统一变量 前言 本篇在讲什么 本篇记录对glsl中的变量uniform的认知和学习 本篇适合什么 适合初学Open的小白 适合想要学习OpenGL中uniform的人 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 …... 编程日记 2023/2/12 12:52:44 🌇个人主页:_麦麦_ 📚今日名言:生活不可能像你想象的那么好,也不会像你想象的那么糟。――莫泊桑《羊脂球》 目录 一、前言 二、正文 1结构体 1.1结构体的基础知识 1.2结构的声明 1.3特殊的声明 1.4结构体变量的…... 编程日记 2023/2/14 1:49:30 ?写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。点击跳转到网站。…... 编程日记 2023/2/15 10:57:22 目录 内置函数 一、日期函数 二、字符串函数 三、数学函数 四、其他函数 内置函数 一、日期函数 函数名称描述current_date()获取当前日期current_time()获取当前时间current_timestamp()获取当前时间戳now()获取当前日期时间date(datetime)获取datetime参数的日期部分d…... 编程日记 2023/2/14 12:59:25 【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型 【论文原文】:DEGREE A Data-Efficient Generation-Based Event Extraction Mode 【作者信息】:I-Hung Hsu , Kuan-Hao Huang, Elizabeth Boschee ÿ…... 编程日记 2023/2/14 22:03:09 类和对象(中)(二)1.赋值运算符重载1.1运算符重载1.2赋值运算符重载1.3前置和后置重载2.const成员3.取地址及const取地址操作符重载🌟🌟hello,各位读者大大们你们好呀🌟🌟…... 编程日记 2023/2/14 9:50:14 2010-2019年290个地级市经济发展与城市绿化数据 1、时间:2010-2019年 2、来源:城市统计NJ,缺失情况与NJ一致 3、范围:290个地级市 4、指标: 综合经济:地区生产总值、人均地区生产总值、地区生产总值增…... 编程日记 2023/2/15 10:58:49 前言:今天我们学习的是C语言中另一个比较熟知的小游戏――扫雷 下面开始我们的学习吧! 文章目录游戏整体思路游戏流程游戏菜单的打印创建数组并初始化布置雷排查雷完整代码game.hgame.ctest.c游戏整体思路 我们先来看一下网上的扫雷游戏怎么玩 需要打印…... 编程日记 2023/2/15 0:11:23 目录 计数器的设计: 计数器的作用: 计数器的实现: 1、用“”函数描述: 用T触发器级联构成的串行进位的二进制加法计数器的仿真波形: 计数器的仿真: 计数器的设计: 计数是一种最简单基本的…... 编程日记 2023/2/12 14:51:44 Java基础知识总结 1. Java语言的特点 简单易学,相较于python等语言具有较好的严谨性以及报错机制; 面向对象(封装,继承,多态),Java中所有内容都是基于类进行扩展的,由类创建的实体…... 编程日记 2023/2/13 17:40:25 作者:小刘在C站 个人主页:小刘主页 每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! 夕阳下,是最美的,绽…... 编程日记 2023/2/14 8:35:14 SpringCloud项目启动过程中会解析bootstrop.properties、bootstrap.yaml配置文件,启动父容器,在子容器启动过程中会加入PropertySourceBootstrapConfiguration来读取配置中心的配置。 PropertySourceBootstrapConfiguration#initialize PropertySource…... 编程日记 2023/2/12 18:47:50 PyTorch学习笔记:nn.L1Loss――L1损失 torch.nn.L1Loss(size_averageNone, reduceNone, reductionmean)功能:创建一个绝对值误差损失函数,即L1损失: l(x,y)L{l1,…,lN}T,lnOxn?ynOl(x,y)L\{l_1,\dots,l_N\}^T,l_n|x_n-y_n| l(…... 编程日记 2023/2/12 18:49:03 记录:374场景:在CentOS 7.9操作系统上,安装node-v14.17.3-linux-x64环境。包括node-v14.17.3和npm-6.14.13。node命令应用和npm命令应用。版本:JDK 1.8 node v14.17.3 npm 6.14.13官网地址:https://nodejs.org/下载地址…... 编程日记 2023/2/13 2:08:59 Oracle Dataguard(主库为 Oracle rac 集群)配置教程(02)―― Oracle RAC 主库的相关操作 / 本专栏详细讲解 Oracle Dataguard(Oracle 版本为11g,主库为双节点 Oracle rac 集群)的配置过程。主要…... 编程日记 2023/2/16 8:41:19 组件和jsx <body><div id"root"></div><script type"text/babel">const root ReactDOM.createRoot(document.getElementById("root"))class App extends React.Component {render() {return (<div> <h1>s…...  插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个整数 n ,请你将…... 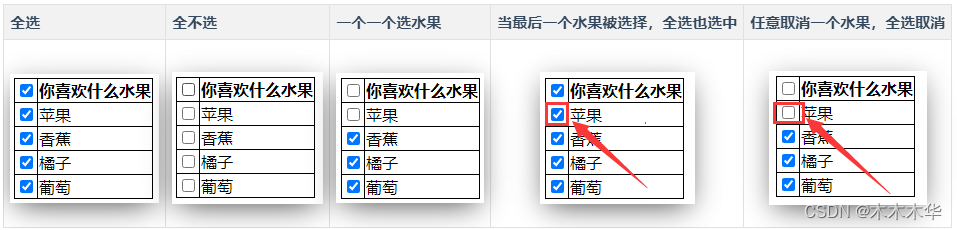 今天,复看了一下JS的菜鸟教程,发现评论里面都是精华呀!! 看到函数这一节,发现就复选框的全选和全不选功能展开了讨论。我感觉挺有意思的,尝试实现了一下。 1. 全选、全不选,两个按钮ÿ…...  先建立一个Maven springboot项目 进来先把src删掉,因为是一个父项目,我们删掉src之后,pom里配置的东西,也能给别的模块使用。 改一下springboot的版本号码 加入依赖和依赖管理: <properties><java.versi…... 图像处理透视变换(Opencv) 文章目录 一. 透视变换定义二. 代码实现2.1. order_points函数2.2. four_point_transform函数2.3. 程序主函数三. 参考文献一. 透视变换定义 【图像处理】透视变换 Perspective Transformation原理:https://blog.csdn.net/xiaowei_cqu/article/detai…... |


